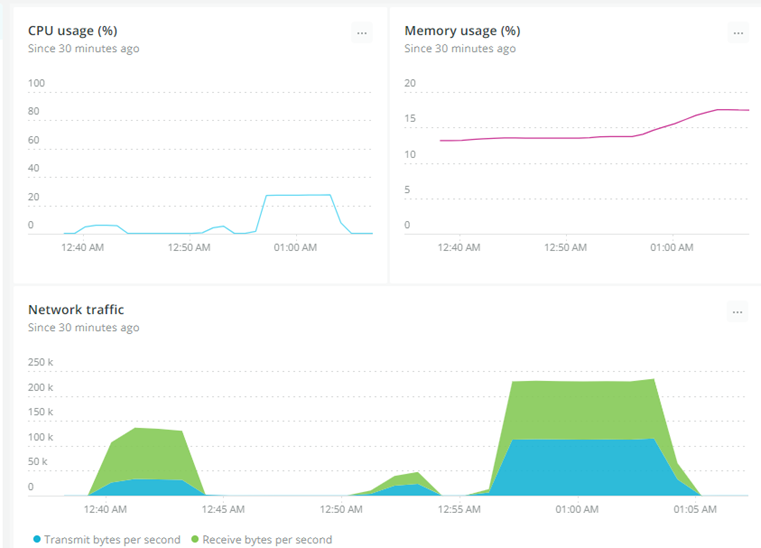
현재 AWS 환경으로 서버를 운영 중에 있는데 메모리 초과로 서버가 계속 다운되는 현상이 지속적으로 발견되었다
워낙 사양이 낮아서 그런가 했지만 서버 상황을 모니터링을 하다 보니 메모리가 계속해서 누적되는 게 원인인 것 같았다
타 부서에서 사용하는 서버인 데다가 python 환경이어서 지식이 아예 없는 상황이었다..
우선은 python을 다뤄본 적이 없어서 그 부분부터 파악이 필요했다
1. 파이썬의 메모리 관리
Python에서는 GC(Garbage Collection)와 레퍼런스 카운트(Reference Counts)에 의해 메모리 관리를 하고 있지만,
순환 참조(자기 자신을 참조)와 같은 코드가 있으면 메모리 누수가 발생할 수 있음.
2. 테스트 계획
조사한 내용에 의하면 소스 코드가 문제인가 싶어서
우선 메모리 누수가 어디서 이뤄지는지 찾기 위해 테스트 계획을 세웠다
- Python의 tracemalloc 라이브러리를 사용하여 API를 호출할 때마다 메모리 할당을 추적.
- 메모리 추적 로그를 통해 원인 분석 및 소스 코드 파악
3. 테스트 결과
결과부터 말하자면 특정 API의 문제가 아니라 Flask로 구동되고 있는 거의 모든 API들이 문제가 있는 걸로 판단되었다
(단순 hello만 출력하는 API만 호출했음에도 메모리 누수가 발생하였고, Flask를 사용하지 않고 로직을 돌렸을 때는 메모리 누수가 발생하지 않았음)
Jmeter와 NewRelic 사용하여 테스트를 진행하였다
- user: 20 / Call: 10,000 (약 8분 소요)
- 메모리
Start: 13.7%
End: 17.5%
=> + 3.8% - CPU: 27%
- 메모리
증가한 메모리가 다시 휘발되지 않음...
4. 구동 환경
flask 프레임워크 환경이었으며,
서버 구동 역시 flask 프레임워크가 제공하는 development 서버를 그냥 띄운 상태였다
자바 쪽과 비교를 하자면 그냥 class 파일을 실행시킨 상태(?)
그렇게 찾다 보니 Gunicorn를 통해 구동하는 방법을 선택하게 되었다
5. Gunicorn
- 사용 이유
- 파이썬 쓰레드는 한 번에 하나 밖에 동작할 수 없음
- 따라서 구조적으로 한번에 많은 트래픽을 처리하기엔 느리다는 단점
- Gunicorn을 사용하여 멀티 프로세스 사용
- Gunicorn은 WSGI HTTP 서버로, 설정이 매우 쉽고 성능이 뛰어나서 많이 활용됨
- 2가지 효과를 기대하며 적용을 준비
- 요청을 1개의 프로세스로 처리하는 기존의 방식이 아닌 다수의 프로세스로 분산하여 처리하는 방식으로 변경
기대효과 : 트래픽이 증가하였을 때, 병목 현상으로 인해 서버가 다운되던 문제를 일정 수준 완화 - 프로세스별로 각각 메모리를 관리하여 일정 수준 누적될 경우 프로세스 재시작을 통해 메모리를 초기화되도록 변경
기대효과 : 메모리 사용량이 초과되어 서버가 다운되던 문제 해결
(그림으로 정리해봄)

- Gunicorn 구동 시 메모리가 높아지는 현상
- 멀티 프로세싱은 여러 개의 프로세스가 별도로 실행되고 각 프로세스가 별개의 메모리를 차지하고 있으며, 멀티 쓰레드는 하나의 프로세스 내에서 메모리를 공유해서 사용
ex) Worker 9개로 구동 시 프로세스가 10개 실행됨 (Master Process 1 + Worker Process 9) - master process는 worker process를 관리하는 역할
- worker process는 웹어플리케이션을 임포트하며, 요청을 받아 웹어플리케이션 코드로 전달하여 처리하도록 하는 역할
6. Gunicorn Worker process Type
- Gunicorn Worker process Type 종류
- sync
- gevent
- gthread
sync는 다른 타입에 비해 낮은 효율. 비교 대상에서 제외했음
gthread vs gevent 비교를 위해 테스트를 진행
(두 타입 모두 최적화 옵션 값을 미리 확인하였음. 추 후 둘 중에 결정된 타입으로 더 정확히 테스트를 진행해야 돼서 적당한 옵션 값을 도출했음)
마찬가지로 Jmeter와 NewRelic을 사용하여 테스트를 진행하였다
- 시작 user 수를 50명으로 설정
- API를 10초 간격으로 호출
- 3분마다 user 수를 20명씩 4번 증가
- 총 50, 20, 20, 20, 20 -> 130 (15분) 동시접속 테스트 진행
| Process Type |
API_1 (Jmeter) 응답시간 |
API_2 (Jmeter) 응답시간 |
API_3 (Jmeter) 응답시간 |
API_4 (Jmeter) 응답시간 |
Memory 점유율 |
API_1 (Jmeter) Error |
API_2 (Jmeter) Error |
API_3 (Jmeter) Error |
API_4 (Jmeter) Error |
| gthread | 23.360s | 24.268s | 25.217s | 24.217s | 37.2% | 0.00% | 0.04% | 0.00% | 0.00% |
| gevent | 13.415s | 18.440s | 15.635s | 13.710s | 64.8% | 16.68% | 18.48% | 20.82% | 15.67% |
- gevent는 gthread에 비해 응답 시간은 빠르지만 에러율이 훨씬 높은 것으로 확인
- gthread 타입을 사용하는 편이 효율적인 것으로 판단
7. Gunicorn gthread 최적화 옵션
gthread를 제대로 사용하기 위해서는 worker, threads 2가지 옵션 값을 설정해야 한다
(worker : 독립적인 프로세스 개수, threads : 각 worker의 thread 개수)
공식 문서에서 권장하는 워커와 스레드의 개수는 2 * $NUM_CPU + 1 였으나 실제로 적용해본 결과는 많이 달랐다
최적 값을 찾기 위해 또 노가다를 시작하였다...
- gthread 테스트 방법
- worker 수와 theads 수를 변경하면서 테스트
- worker -> 4, 9
- theads -> 2, 4, 6 ,8, 10
- 시작 user 수를 50명으로 설정
- API의 종류는 부하가 가장 심한 4개로 선정
- API를 10초 간격으로 호출
- 3분마다 user 수를 20명씩 4번 증가
- 총 50, 20, 20, 20, 20 -> 130 (15분) 동시접속 테스트 진행
| Worker | Thread | API_1 (Jmeter) 응답시간 |
API_2 (Jmeter) 응답시간 |
API_3 (Jmeter) 응답시간 |
API_4 (Jmeter) 응답시간 |
Memory 점유율 |
API_1 (Jmeter) Error |
API_2 (Jmeter) Error |
API_3 (Jmeter) Error |
API_4 (Jmeter) Error |
| 2 | 8 | 35.028s | 40.996s | 36.178s | 36.588s | 28% | 0.00% | 0.24% | 0.05% | 0.00% |
| 2 | 16 | 36.268s | 52.657s | 37.519s | 42.173s | 28% | 0.00% | 0.07% | 0.06% | 0.00% |
| 4 | 4 | 22.895s | 27.3361s | 22.706s | 23.077s | 46% | 0.00% | 0.27% | 0.12% | 0.00% |
| 4 | 6 | 22.160s | 30.820s | 22.875s | 23.329s | 46% | 0.00% | 0.15% | 0.04% | 0.00% |
| 4 | 8 | 19.375s | 28.276s | 19.68s | 20.3s | 53% | 0.00% | 0.14% | 0.28% | 0.00% |
| 4 | 10 | 19.949s | 35.165s | 21.016s | 21.533s | 55% | 0.00% | 0.22% | 0.04% | 0.00% |
| 4 | 16 | 17.905s | 40.416s | 19.657s | 20.378s | 55% | 0.00% | 0.25% | 0.25% | 0.00% |
| 6 | 4 | 25.933s | 35.006s | 25.878s | 27.316s | 68% | 0.00% | 0.12% | 0.12% | 0.00% |
| 6 | 6 | 23.626s | 36.858s | 24.467s | 26.477s | 68% | 0.00% | 0.30% | 0.11% | 0.00% |
| 6 | 8 | 21.379s | 39.916s | 21.320s | 23.732s | 72% | 0.00% | 0.07% | 0.22% | 0.00% |
| 6 | 16 | 17.137s | 49.892s | 16.600s | 24.781s | 70% | 0.51% | 1.14% | 1.14% | 0.92% |
| 9 | 8 | 25.277s | 44.253s | 23.700s | 26.313s | 70% | 0.69% | 0.43% | 0.43% | 1.16% |
| 9 | 16 | 21.614s | 54.696s | 19.418s | 28.474s | 85% | 0.69% | 2.93% | 0.43% | 1.16% |
- 4 Worker 기준으로 재측정
| Worker | Thread | API_1 (Jmeter) 응답시간 |
API_2 (Jmeter) 응답시간 |
API_3 (Jmeter) 응답시간 |
API_4 (Jmeter) 응답시간 |
Memory 점유율 |
API_1 (Jmeter) Error |
API_2 (Jmeter) Error |
API_3 (Jmeter) Error |
API_4 (Jmeter) Error |
| 4 | 1 | 23.360s | 24.268s | 25.217s | 24.217s | 37.20% | 0.00% | 0.04% | 0.00% | 0.00% |
| 4 | 2 | 21.258s | 21.616s | 22.324s | 22.375s | 39.50% | 0.00% | 0.25% | 0.05% | 0.00% |
| 4 | 4 | 24.613s | 31.410s | 28.786s | 27.517s | 45.00% | 0.00% | 0.20% | 0.05% | 0.00% |
| 4 | 6 | 22.537s | 30.608s | 24.003s | 24.167s | 46.60% | 0.00% | 0.05% | 0.08% | 0.00% |
| 4 | 8 | 19.966s | 32.338s | 20.448s | 21.796s | 49.30% | 0.00% | 0.10% | 0.04% | 0.00% |
| 4 | 10 | 21.005s | 37.328s | 21.905s | 23.397s | 56.00% | 0.00% | 0.06% | 0.11% | 0.00% |
- 측정 결과
- worker, Thread 개수가 증가할수록 메모리 점유율이 높음
- worker, Thread 개수를 높게 설정할 경우 에러율이 급격하게 증가됨
- worker - 4, Thread - 1 일 때 가장 효율이 좋았음 (속도, 에러율 기준)
8. Gunicorn - max-request, max-requests-jitter 최적화 옵션
마지막으로 max-request, max-requests-jitter 옵션 값을 설정하기 위해 테스트를 진행했다
마찬가지로 최적의 값을 찾아야 함.. 이 역시 시스템 환경마다 최적 값이 다르다
(max-request: 해당 request 수만큼 처리가 완료되면 worker를 재시작함. 이 기능을 통해 메모리를 초기화하여 관리할 수 있게 된다
max-requests-jitter: 모든 worker가 동시에 재시작되는 현상을 막기 위해서 max-requests-jitter 범위 내에 랜덤 한 값을 max-request 값에 더해준다)
- max-request, max-requests-jitter 테스트 방법
- max-requests 수와 max-requests-jitter 수를 변경하면서 테스트
- max-requests -> 1000, 750, 500
- max-requests-jitter -> 50, 500
- API의 종류는 부하가 가장 심한 4개로 선정
- API 별로 각각 시작 user 수 25명
- API 별로 0초 간격으로 100번씩 호출
| Worker | Thread | Max requests |
Max Requests jiter |
API 종류 |
user | loop | (Jmeter) 응답시간 |
(Jmeter) Error |
시작 메모리 |
종료 메모리 |
Test Count |
총 시간 |
| 4 | 1 | 1000 | 50 | API_1 | 25 | 100 | 8.363s | 0.00% | 36.50% | 37.40% | 2500 | 00:15:39 |
| API_2 | 25 | 100 | 8.936s | 0.08% | 2500 | |||||||
| API_3 | 25 | 100 | 8.528s | 0.00% | 2500 | |||||||
| API_4 | 25 | 100 | 8.319s | 0.04% | 2500 | |||||||
| 4 | 1 | 750 | 50 | API_1 | 25 | 100 | 8.376s | 0.00% | 36.90% | 29.90% | 2500 | 00:15:44 |
| API_2 | 25 | 100 | 8.976s | 0.12% | 2500 | |||||||
| API_3 | 25 | 100 | 8.475s | 0.00% | 2500 | |||||||
| API_4 | 25 | 100 | 8.623s | 0.00% | 2500 | |||||||
| 4 | 1 | 500 | 50 | API_1 | 25 | 100 | 9.026s | 0.00% | 37.30% | 32.40% | 2500 | 00:16:02 |
| API_2 | 25 | 100 | 9.139s | 0.00% | 2500 | |||||||
| API_3 | 25 | 100 | 8.800s | 0.12% | 2500 | |||||||
| API_4 | 25 | 100 | 9.120s | 0.08% | 2500 | |||||||
| 4 | 1 | 1000 | 500 | API_1 | 25 | 100 | 8.044s | 0.00% | 37.40% | 34.90% | 2500 | 00:15:26 |
| API_2 | 25 | 100 | 8.755s | 0.04% | 2500 | |||||||
| API_3 | 25 | 100 | 8.134s | 0.04% | 2500 | |||||||
| API_4 | 25 | 100 | 8.313s | 0.00% | 2500 | |||||||
| 4 | 1 | 750 | 500 | API_1 | 25 | 100 | 8.315s | 0.00% | 37.50% | 37.30% | 2500 | 00:15:35 |
| API_2 | 25 | 100 | 8.667s | 0.04% | 2500 | |||||||
| API_3 | 25 | 100 | 7.652s | 0.00% | 2500 | |||||||
| API_4 | 25 | 100 | 8.029s | 0.00% | 2500 | |||||||
| 4 | 1 | 750 | 500 | API_1 | 25 | 100 | 8.251s | 0.00% | 37.50% | 37.30% | 2500 | 00:15:24 |
| API_2 | 25 | 100 | 8.901s | 0.04% | 2500 | |||||||
| API_3 | 25 | 100 | 8.454s | 0.08% | 2500 | |||||||
| API_4 | 25 | 100 | 8.178s | 0.00% | 2500 |
- 측정 결과
max-requests 값에 따른 큰 차이는 없었음
9. Gunicorn vs Flask - Stress Test (부하 테스트)
Gunicorn을 적용할 준비를 끝내고 마지막으로 기존 Flask와 어느 정도 차이인지 확인하기 위해 테스트를 진행하였다
- Gunicorn vs Flask 성능 비교 테스트 방법
- API의 종류는 부하가 가장 심한 4개로 선정
- API 별로 각각 시작 user 수 25명
- API 별로 0초 간격으로 100번씩 호출
| API 종류 | user | loop | (Jmeter) 응답시간 |
(Jmeter) Error |
시작 Memory |
종료 Memory |
Test Count | 총 시간 | |
| Gunicorn | API_1 | 25 | 100 | 8.315s | 0.00% | 37.50% | 37.30% | 2500 | 00:15:35 |
| API_2 | 25 | 100 | 8.667s | 0.04% | 2500 | ||||
| API_3 | 25 | 100 | 7.652s | 0.00% | 2500 | ||||
| API_4 | 25 | 100 | 8.029s | 0.00% | 2500 | ||||
| Flask (1차 측정) |
API_1 | 25 | 100 | 3.808s | 0.00% | 37.50% | 37.30% | 2500 | 00:37:42 |
| API_2 | 25 | 100 | 22.540s | 0.12% | 2500 | ||||
| API_3 | 25 | 100 | 2.694s | 0.16% | 2500 | ||||
| API_4 | 25 | 100 | 6.240s | 0.00% | 2500 | ||||
| Flask (2차 측정) |
API_1 | 25 | 100 | 3.776s | 0.00% | 37.50% | 37.30% | 2500 | 00:37:36 |
| API_2 | 25 | 100 | 22.463s | 0.04% | 2500 | ||||
| API_3 | 25 | 100 | 2.686s | 0.12% | 2500 | ||||
| API_4 | 25 | 100 | 6.279s | 0.00% | 2500 |

- 측정 결과
- Flask가 에러율이 조금 더 높았으며, 총시간은 Gunicorn을 사용한 경우가 압도적으로 빨랐음
- Gunicorn의 경우 균등하게 트래픽을 처리
- Flask의 경우 처리량이 적어 요청이 계속 누적됨 (처리 속도 저하)
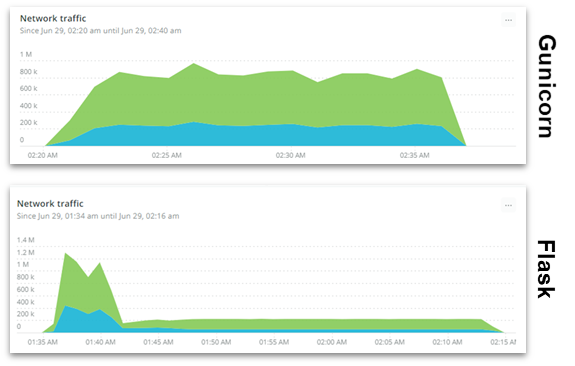
10. Gunicorn vs Flask - Peak Test (동시접속 테스트)
하는 김에 Peak Test도 함께 진행했다
- Gunicorn vs Flask 성능 비교 테스트 방법
- API의 종류는 부하가 가장 심한 4개로 선정
- user 수를 증가시키며 API를 동시 호출
- 에러율이 높은 경우 user 수를 감소시키고, 에러율이 0이거나 낮을 경우 user 수를 증가시키며 테스트
| API | user | loop | (Jmeter) 응답시간 |
(Jmeter) Error |
시작 Memory |
종료 Memory |
Test Count | 총 시간 | |
| Gunicorn | API_1 | 500 | 1 | 23.545s | 0.00% | 38.20% | 37.50% | 2000 | 00:03:12 |
| API_2 | 500 | 1 | 106.514s | 0.00% | |||||
| API_3 | 500 | 1 | 76.017s | 0.00% | |||||
| API_4 | 500 | 1 | 74.871s | 0.00% | |||||
| Flask | API_1 | 125 | 1 | 11.907s | 0.00% | 19.60% | 19.80% | 500 | 00:01:54 |
| API_2 | 125 | 1 | 72.991s | 0.00% | |||||
| API_3 | 125 | 1 | 10.215s | 0.80% | |||||
| API_4 | 125 | 1 | 24.334s | 10.40% | |||||
| Flask | API_1 | 100 | 1 | 14.268s | 0.00% | 13.50% | 13.90% | 400 | 00:01:42 |
| API_2 | 100 | 1 | 69.920s | 0.00% | |||||
| API_3 | 100 | 1 | 12.848s | 0.00% | |||||
| API_4 | 100 | 1 | 32.956s | 0.00% |
- 측정 결과
Peak Test (동시접속 테스트)에서 더 큰 차이를 보였음
11. 최종 결론
Gunicorn 적용하는 것이 Flask를 단독으로 사용했을 때 보다 처리량이나 안정성 등이 높다고 판단됨
- 최종 Gunicorn 최적화 옵션
worker : 4
threads : 1
worker process Type : gthread
max-requests : 750
max-requests-jitter : 500
옵션의 경우 시스템 환경(사양이나 서버 환경)등에 따라 차이가 있기 때문에 타 서버에 이 옵션을 적용할 필요는 없다
- 현재 서버에 적용함으로써 얻을 수 있는 기대효과
- 기존보다 안정적으로 많은 양을 처리 (처리량이 많으면 많을수록 차이가 더 클 것으로 보임)
- 기존 Flask를 사용했을 경우 동시에 처리할 수 있는 API : 400 (Peak Test 기준)
- Gunicorn을 적용하였을 경우 동시에 처리할 수 있는 API : 2000 (Peak Test 기준)
- 프로세스 재실행 옵션으로 메모리 관리가 일정 수준 가능할 것으로 판단
기존 환경보다는 훨씬 개선된 결과를 테스트를 통해 확인했으니 고생한 보람이 있었다고 생각해야겠음..
더 개선할만한 방법이 있는지 계속 찾아봐야겠다
ps. CPU + GPU를 사용하여 요청을 처리하도록 개선을 해봤는데 서버 비용에 비해 효율이 너무 떨어져서 제외했다 (비용에 비해 큰 차이가 없었음)
'개발 지식 > DevOps' 카테고리의 다른 글
| DB I/O bound 애플리케이션 + Message Queue (0) | 2023.04.02 |
|---|---|
| Nginx를 통한 로드밸런싱 + 무중단 배포 (1) | 2023.03.16 |
| Jenkins 배포 환경 구축 (0) | 2023.03.11 |
| 간단한 Docker 환경 구축하기 (0) | 2023.03.11 |
| CPU bound Test (0) | 2023.03.08 |